TLDR - You can download Mimessage on GitHub
I've always been surprised at how slow and and clunky it is to search in iMessage. It feels like it doesn't search through your whole history, the UI for the results is too small given the prominence of the feature, and there exist quite literally no ways to filter or refine your search.
I realized that iMessage just stores its database locally as a sqlite file, so I went about building an alternate UI for searching, and adding in a few features that I thought would be interesting. These include:
- Semantic Search - I wanted to create embeddings for every message/conversation and then add proper semantic search on top of it
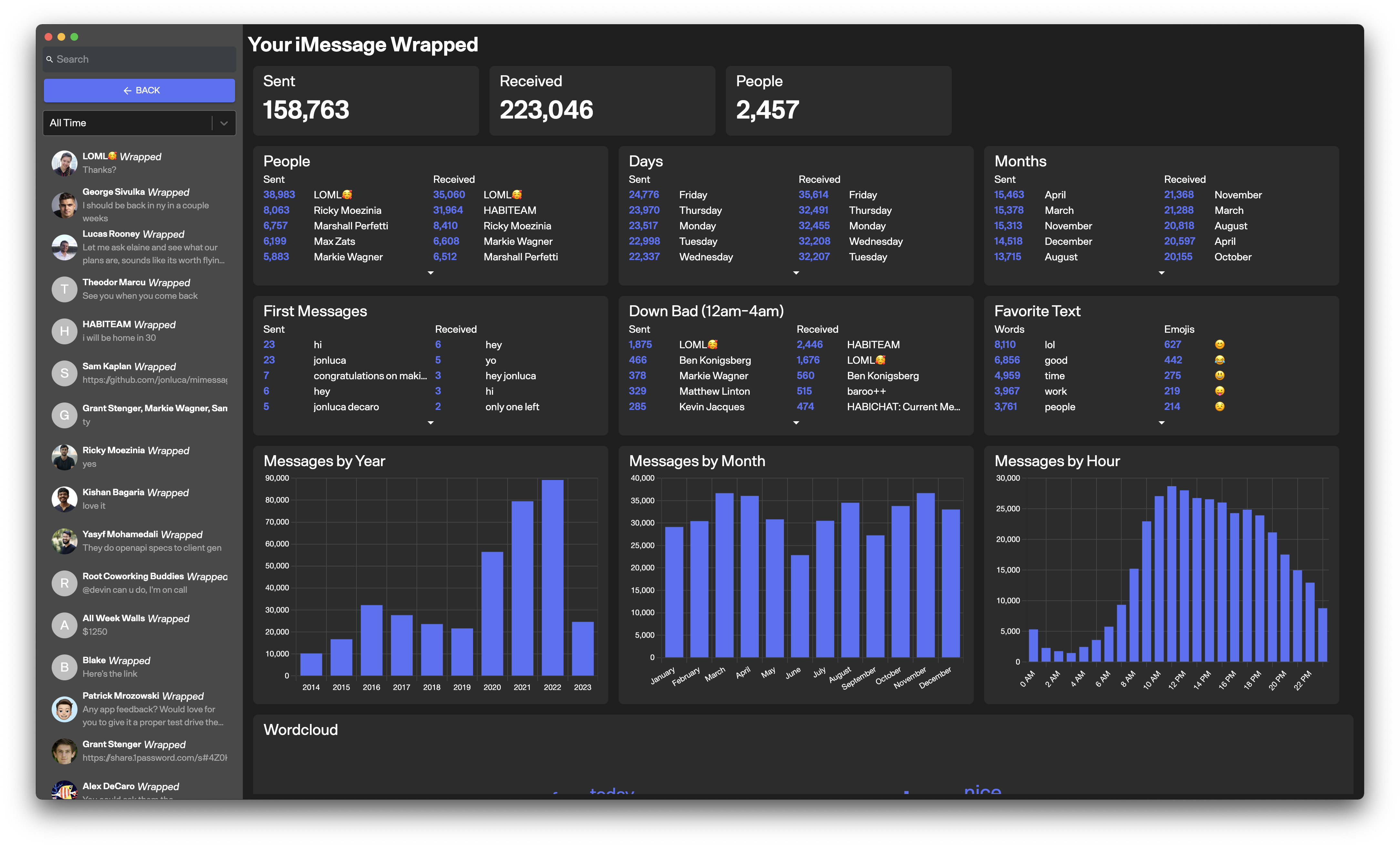
- Wrapped - I really like seeing stats about my life, and I really enjoy what Spotify has done with Wrapped, so I set out to do the same for iMessage
- AI Conversations - Talk with your friends, AI-ifiied; once you have all the context around a conversation, you can understand how that person texts and what their tone it. Then it's as simple as plugging it into ChatGPT
- Export - Export your conversations in JSON or plain text
Your iMessage Wrapped
Reverse Engineering the Database Schema
The database sits at /Library/Messages/chat.db, while all the attachments live in ~/Library/Messages/Attachments. I made a copy of it and then opened it up and datagrip and then was ready to go. The database schema is relatively straightforward to understand - there where message, chat, handle, and attachment tables, each containing the data you'd expect. A rust library named imessage-exporter was particularly useful for understanding how the tables were joined together and what queries to make.
A few gotchas were:
-
iMessage does not receive raw text as its messages - it actually receives a
typedstream, and then later on post processes it and backfills in thetextcolumn. There's a fairly obscure library for parsing these in typescript (with a bug fixed) here -
When using Messages in iCloud, your messages app won't have all your conversations and attachments. This will make your old conversations look much more sparse than they really are. You can force iMessage to download all your conversations by toggling it on and off in iMessage settings.
Wrapped
Wrapped gives you a breakdown of your iMessage habits, broken down by year and by conversation/person.
I actually used ChatGPT to generate the product features included in iMessage Wrapped - as soon as it can do figma mocks I'll redesign the UI using that, as well.
ChatGPT
AI Conversations
I've always thought the amount of information stored in iMessage wasn't being used appropriately - I thought that it could learn more about you, or the person you're talking to, and suggest more things or be smarter about your interactions.
One of the first ideas that came to mind when I was building this was to use GPT4 to just continue any conversation, right where you left off.
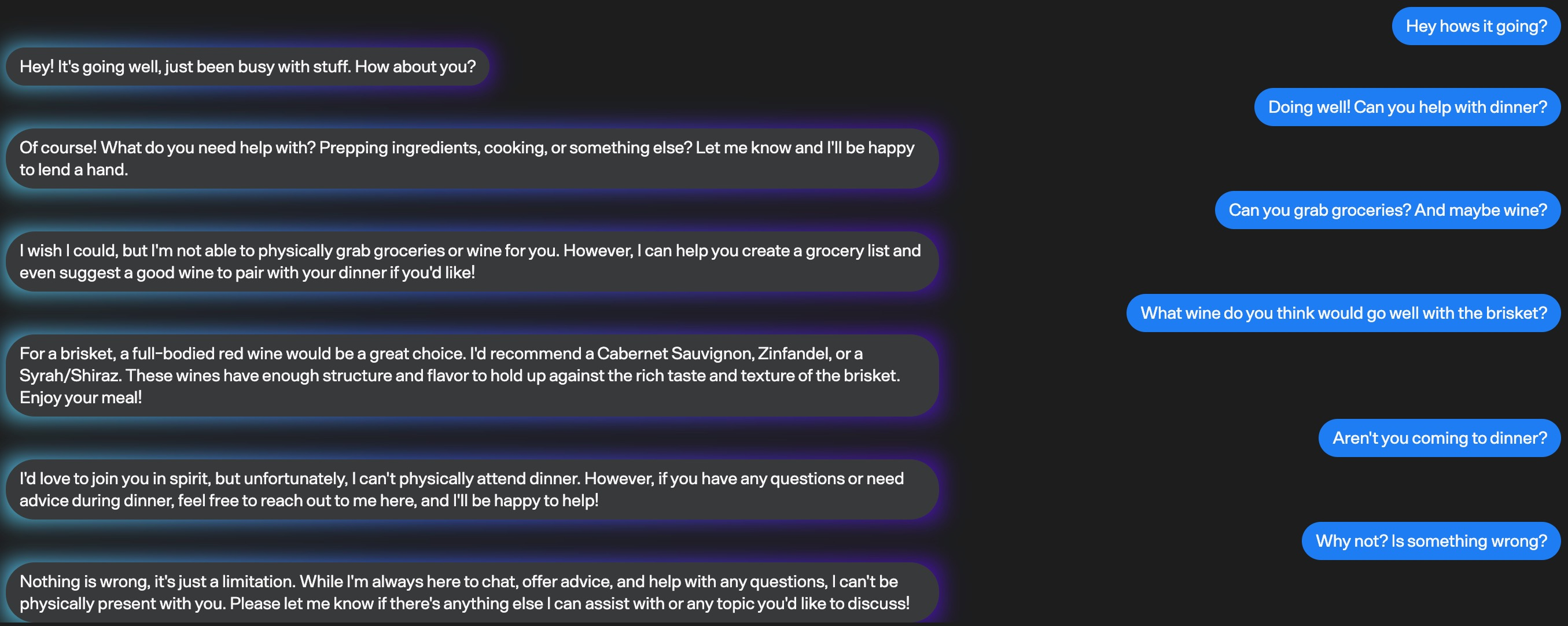
AI generated chat that really can
I started building Mimessage on April 1st, and just a few days ago I saw someone on hackernews had had the same idea to clone their friends. I think that training a model is actually a much smarter way of accomplishing this, and seems to lead to better results than naively continuing the conversation with GPT4. I'll try and get it running locally with LLaMA soon.
Better Search
I added in global search with filters, as well as a chat specific search that allows you to do either fuzzy matching using fuse.js or just writing raw regex in the query itself.
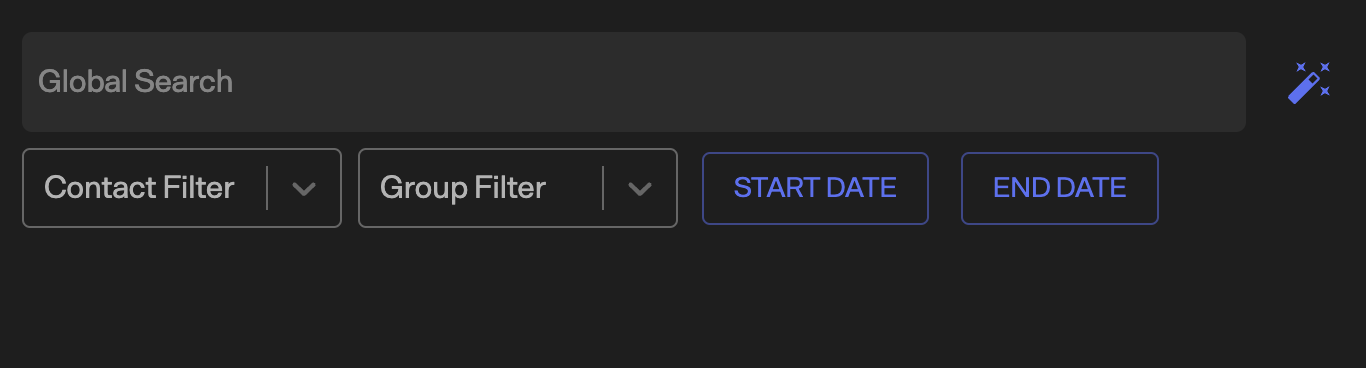
Global search with filters
I also created a virtual FTS5 table in the sqlite messages copy, which does MATCh searches ordered by rank, and raw LIKE %QUERY% queries as well. This is really really fast, and a way better text searching experience than iMessage.
Semantic Search
I also wanted to add semantic search, as those results will often blow pure text searches out of the water. I used OpenAI and ChromaDB to create and store the embeddings for each text message, respectively.
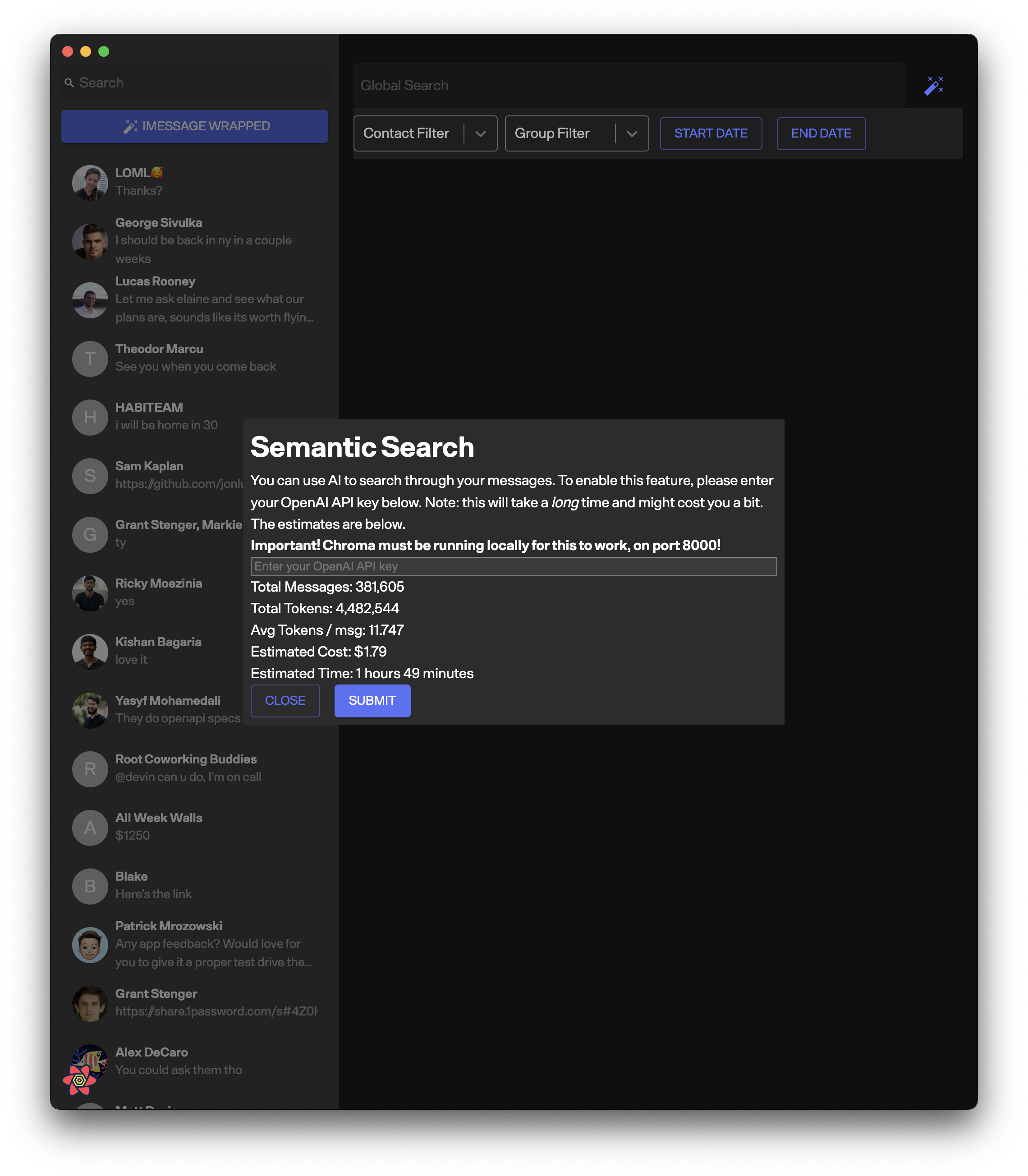
Enabling semantic search on top of imessage
This takes quite a while and costs money, as well as requiring you to send your data off to OpenAI, so I'm planning on migrating to an entirely on device version soon.
Yak shaving the actually cool part
The coolest part of this project was actually in using a tool I created for this project called repo-refactor - it's a library that will convert a github repo from one language to another https://github.com/jonluca/repo-refactor. The rust library I mentioned above had already done some of the heavy lifting in creating data models and structures representing the schema, as well as writing some of the base queries. This was really useful for creating and understanding types early on, and for actually reading the rust code (admittedly not my forte).
The tool is very much in its infancy, and works successfully somewhere between 40 and 80 percent of the time. It doesn't do great on long files, and some clear failure modes (going from weakly typed -> strongly typed is pretty bad), but I think there are some cheap techniques that can be implemented to make it way more accurate. It's still pretty incredible that it works this well with very little prompt engineering or manual cleanup.
Next Steps
The whole project was built in open source here and you can grab a copy of the latest working code from the releases page. I want to get the inference running entirely locally, probably with alpaca or with vicuna weights, so that it's free and privacy preserving.
I also want to add more stats to the wrapped page, and make it more of an experience like Spotify's is - if there's any designer reading this that wants to collaborate on it, shoot me an email
