/r/churning is a subreddit dedicated to maximizing credit rewards and travel hacking. The subreddit has a fairly unique template for activity that is fairly distinct from the rest of reddit - discussions are mostly siloed in weekly threads, with only the rare top level post. I thought it would be interesting to run an analysis of user behavior and activity in the sub, as well as find patterns in the distribution of content.
Getting the data
There's a data archival service called pushshift.io that is collecting data from reddit and making it available to all, for free. I wrote a simple python script that paginated the results and saved them locally.
import requests
import json
url = 'https://api.pushshift.io/reddit/search/comment/?subreddit=churning&sort=desc&size=500'
start_from = ''
num = 1
def save(filename, data):
with open(filename + '.json','w') as out:
out.write(data)
out.close()
while True:
data = requests.get(url+start_from)
try:
res = json.loads(data.text)
# add 1 in case there are any comments that were submitted at the same time
last_utc = str(res['data'][-1]['created_utc'] + 1)
start_from = '&before=' + last_utc
# Flush to disk every time - creates lots of files, but better on their servers in case this fails
# halfway through and we lose everything in memory (happened multiple times :()
save(last_utc, data.text)
num += 1
print(num)
except Exception as e:
passIt was quick and dirty but it got the job done (I normally write these scripts so they keep everything in memory and then flush it to disk at the end, but I've been burned where the requests fail halfway through and I have to restart from the beginning - way easier to piece together each individual 500-comment sized request in another script later on.). I also made it serialized as to respect the wishes of the maintainer, and stuck to around 1 request per second.
Parsing and loading the data
I then loaded all the data into a MySQL database, so that I could query it easily (and, more importantly, do full text searches).
I first defined two helper classes, that implemented a thread pool to improve performance. Due to the global interpreter lock multithreading isn't as helpful in Python as it is in other languages, but it can still provide some significant gains on heavy I/O operations, such as network requests or disk reads/writes.
from queue import Queue
from threading import Thread
class Worker(Thread):
""" Thread executing tasks from a given tasks queue """
def __init__(self, tasks):
Thread.__init__(self)
self.tasks = tasks
self.daemon = True
self.start()
def run(self):
while True:
func, args, kargs = self.tasks.get()
try:
func(*args, **kargs)
except Exception as e:
# An exception happened in this thread
print(e)
finally:
# Mark this task as done, whether an exception happened or not
self.tasks.task_done()
class ThreadPool:
""" Pool of threads consuming tasks from a queue """
def __init__(self, num_threads):
self.tasks = Queue(num_threads)
for _ in range(num_threads):
Worker(self.tasks)
def add_task(self, func, *args, **kargs):
""" Add a task to the queue """
self.tasks.put((func, args, kargs))
def map(self, func, args_list):
""" Add a list of tasks to the queue """
for args in args_list:
self.add_task(func, args)
def wait_completion(self):
""" Wait for completion of all the tasks in the queue """
self.tasks.join()Then I used the peewee python MySQL ORM to define a very light wrapper.
import json
from peewee import *
mysql_db = MySQLDatabase('churning', user="root", host="127.0.0.1", port=3308)
from queue import Queue
from threading import Thread
class BaseModel(Model):
"""A base model that will use our MySQL database"""
class Meta:
database = mysql_db
class Comments(BaseModel):
author = CharField()
author_flair_text = CharField(null=True)
body = TextField()
created_utc = TimestampField()
id = CharField(unique=True, index=True, primary_key=True)
link_id = CharField()
parent_id = CharField()
permalink = CharField(null=True)
keys = ['author', 'author_flair_text', 'body', 'created_utc', 'id', 'link_id', 'parent_id', 'permalink', ]
# Connect to our database.
mysql_db.connect()
mysql_db.execute_sql("SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci;")
# Create the tables.
# mysql_db.drop_tables([Comments])
mysql_db.create_tables([Comments], safe=False)Finally I could define the helper function and thread mapper that would insert the data into the database.
def read_and_insert(filename):
with open(str(filename) + '.json') as cont:
data = json.loads(cont.read())
for entry in data['data']:
all_keys = list(entry.keys())
for key in all_keys:
if key not in keys:
del entry[key]
with mysql_db.atomic():
# Fastest way to INSERT multiple rows.
Comments.insert_many(data['data']).on_conflict_ignore().execute()
print(filename)
pool = ThreadPool(5)
values = [i for i in range(1, 3670)]
pool.map(read_and_insert, values)
pool.wait_completion()This will create a pool of 5 threads. These 5 threads will continue to pull from the queue until there are no more tasks left. I originally created 3669 json files, each with around 500 comments. There were definitely cleaner ways of accomplishing this, but it was just meant to get the job done quickly.
I ran into Unicode errors for emojis in the body - this was fixed by setting the utf8mb4_unicode_ci character encoding to the table with mysql_db.execute_sql("SET NAMES utf8mb4 COLLATE utf8mb4_unicode_ci;")
Analyzing the data
Once I had the data imported to MySQL I optimized it and added all the indexes I needed. The final schema was:
CREATE TABLE `comments` (
`id` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`author` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`author_flair_text` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`body` text COLLATE utf8mb4_unicode_ci NOT NULL,
`created_utc` bigint(20) NOT NULL,
`link_id` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`parent_id` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`permalink` varchar(255) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `author` (`author`),
KEY `id` (`id`),
KEY `time` (`created_utc`),
KEY `author_flair_text` (`author_flair_text`),
KEY `permalink` (`permalink`),
FULLTEXT KEY `body` (`body`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ciThere's a few great plug-and-chug services that will automatically slice your data a few ways. This was pretty much time series data, so I decided to use Grafana for some preliminary analysis.
This worked pretty much out of the box. I set up a simple query for daily comment counts and got the data back immediately.
SELECT
created_utc DIV 86400 * 86400 AS "time",
count(created_utc) AS "created_utc"
FROM comments
WHERE
created_utc >= 1535759470 AND created_utc <= 1567295470
GROUP BY 1
ORDER BY created_utc DIV 86400 * 86400Over the last year we have The resulting graph shows how our comment activity is fairly cyclical. Our weekends are the slowest times, with a quick bounce back on Mondays. We peak on Wednesday/Thursday, and then drop again.
Our deepest dip in the chart is unsurprisingly December 25th, or Christmas, which makes sense as a majority of our userbase is based in Western countries.

one year of churning comments
1 year of /r/churning comments
Our distribution of comments per day is interesting as well.
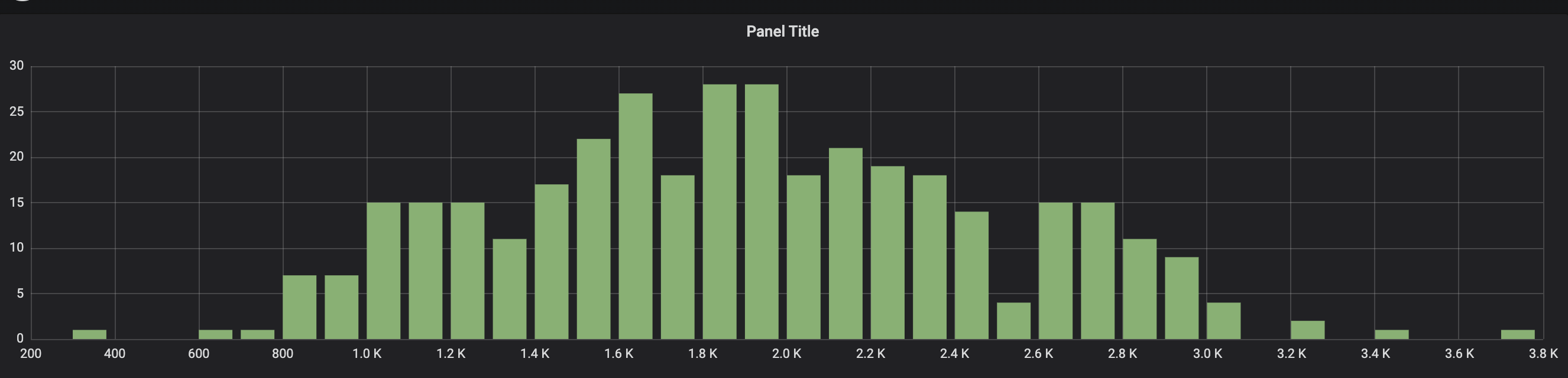
one year of churning comments
Daily comment distribution
Our actual baseline stats put us at around 2,000 comments a day on average. This is actually down year over year - last year, we averaged around 2,400 comments a day.
| Min | Max | Average | Total |
|---|
| Aug '18 - Aug '19 | 260 | 3,789 | 1,925 | 706,443 |
| Aug '17 - Aug '18 | 801 | 4,475 | 2,409 | 884.090 |
Users
The 20 users with the most comments in the last 2 years are below.
| User | Number of Comments |
|---|
| OJtheJEWSMAN | 48622 |
| duffcalifornia | 14221 |
| POINTSmetotheMILES | 14204 |
| aksurvivorfan | 13268 |
| lenin1991 | 8980 |
| Jeff68005 | 8303 |
| the_fit_hit_the_shan | 7810 |
| garettg | 7464 |
| m16p | 7181 |
| AutoModerator | 7046 |
| PointsYak | 6890 |
| cowsareverywhere | 6748 |
| ilessthanthreethis | 6645 |
| payyoutuesday | 5944 |
| bplturner | 5714 |
| Eurynom0s | 5686 |
| TheTaxman_cometh | 5602 |
| blueeyes_austin | 5554 |
| Andysol1983 | 5440 |
We can also look at the distribution of users that comment. We actually really only have one outlier, u/OJtheJEWSMAN. If we remove that account, our distribution looks like a pretty typical Pareto distribution. This year, OJ has made 14,710 comments, which accounts for roughly 2% of all comments on the subreddit.
The top 500 users are also responsible for 366,038 of the comments from last year, or 51.8% of all comments. This follows a pretty typical distribution of online activity (see the 90 - 9 - 1 rule).
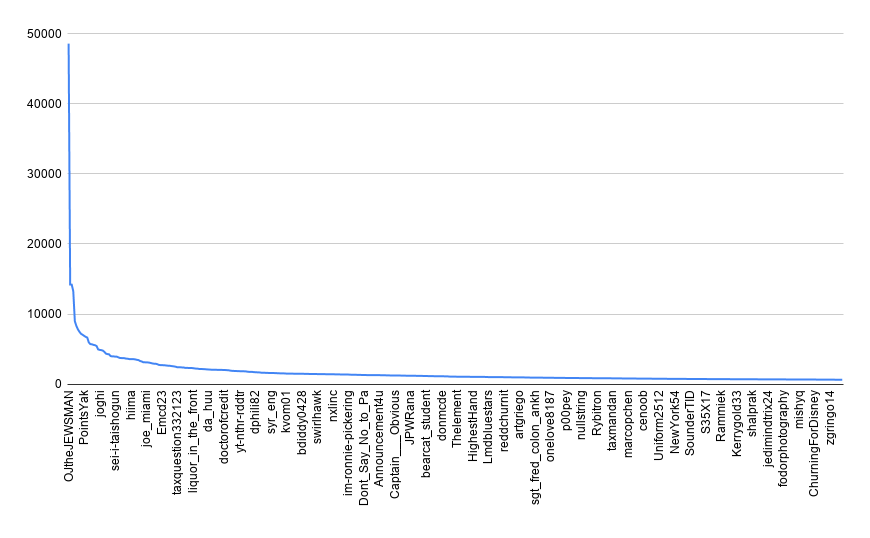
one year of churning comments by user
Top 1000 user comment distribution
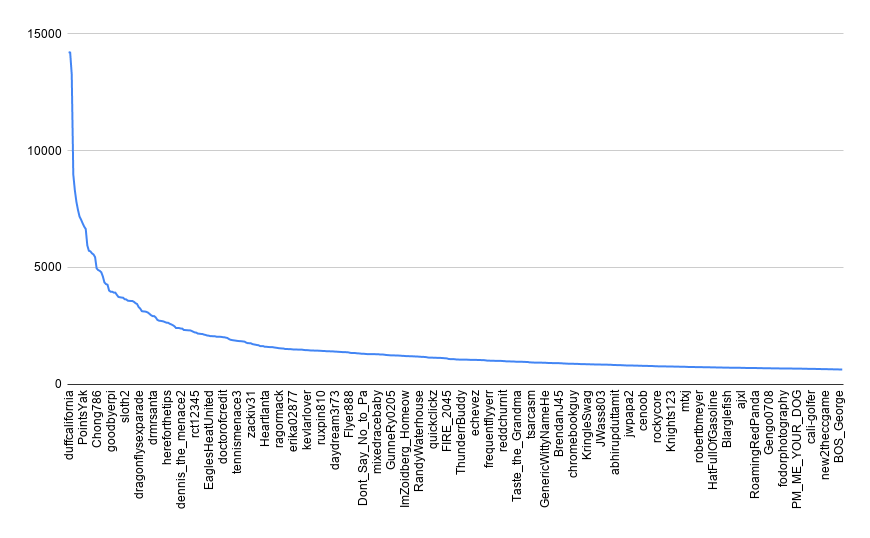
one year of churning comments by user
Top 1000 user comment distribution, without outlier
Just for fun I also looked at OJs daily activity - looks like they took a pretty signifcant break June of 2018, perhaps using up all those hard earned miles on vacation?

one year of churning comments
OJs activity
Data
If you would like to run your own analysis, or get a copy of the data I used here, I uploaded a compressed version of the SQL dump here. You can restore this using bunzip2 < dump.sql.bz2 | mysql -u $USER -p.
I'm open to suggestions on what other metrics to look at! I think it would be cool to visualize who the top 5 commenters have been over time, or perhaps what the average amount of time a user has been active on the subreddit. These might be incorporated in the next State of the Subreddit.
