I do a lot of web scraping in my spare time, and have been chasing down different formats and code snippets to make a large amount of network requests locally, with controls for rate limiting and error handling.
I've gone through a few generations - I'll use this post to catalogue where I started and what I'm doing now. If you want to skip the post and just see the final code, it can be found here.
Gen 1
Generation one was trusty old requests. Need to make 10 requests? Wrap it in a for loop and make them iteratively.
import requests
results = {}
for i in range(10):
resp = requests.get('https://jsonplaceholder.typicode.com/todos/1')
results[i] = resp.json()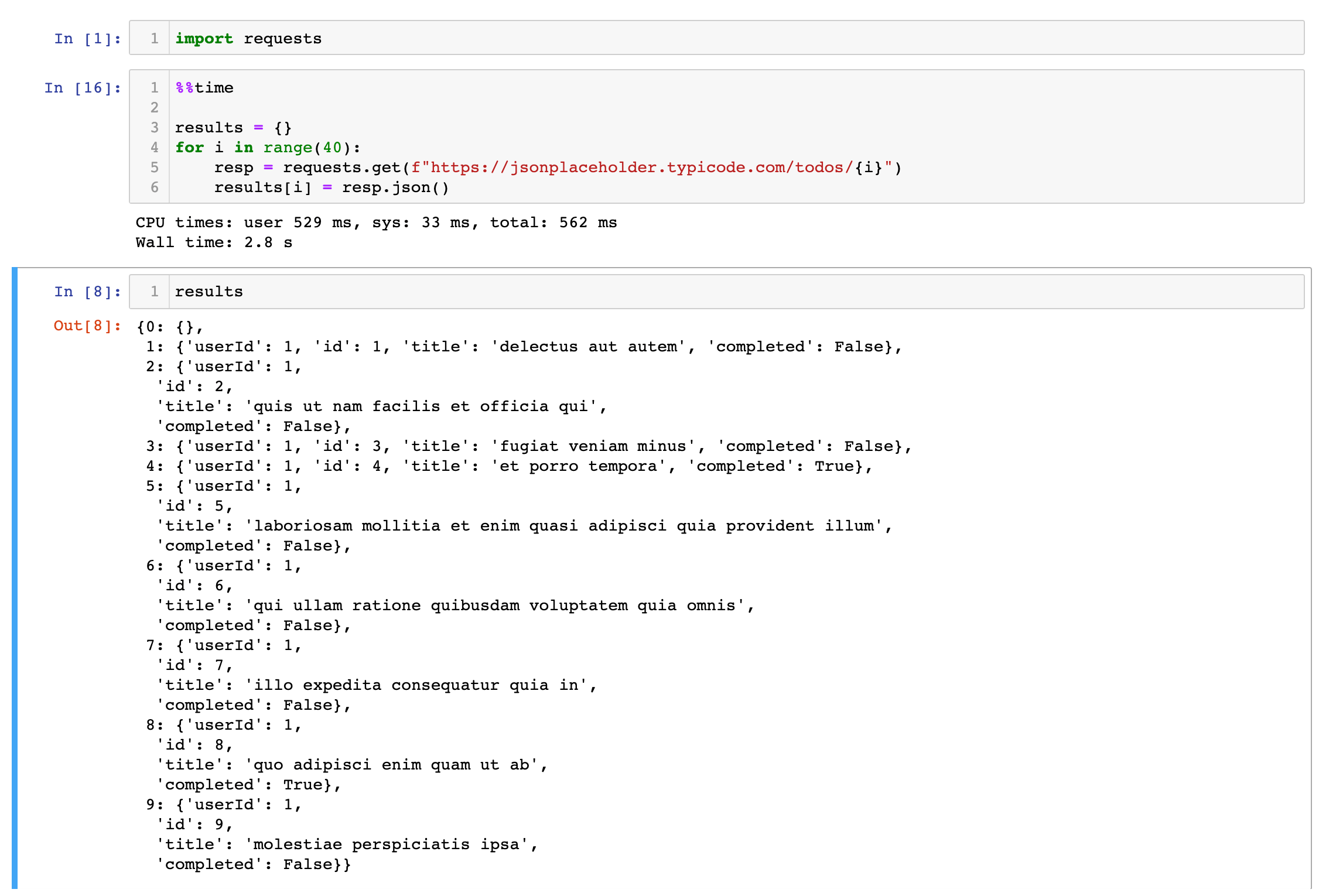
This isn't bad - 40 requests in 2.8s, or 1 req/70ms. Not an issue at all. This is fine when you need to bruteforce a 3 digit passcode - you can get 1000 requests done in 70s. Not great, but fast enough, and no need for external libraries or any research.
As soon as you get to something in the 4 character range, though, this becomes unwieldy.
Gen 2
The next step here was to find ways to make these requests using Threads. Spin off a native thread for each request, and let them run behind the scenes.
Set up a queue and pool to pull URLs from, and we're good. The queue and Worker threads are defined pretty simply below:
from queue import Queue
from threading import Thread
class Worker(Thread):
""" Thread executing tasks from a given tasks queue """
def __init__(self, tasks):
Thread.__init__(self)
self.tasks = tasks
self.daemon = True
self.start()
def run(self):
while True:
func, args, kargs = self.tasks.get()
try:
func(*args, **kargs)
except Exception as e:
# An exception happened in this thread
print(e)
finally:
# Mark this task as done, whether an exception happened or not
self.tasks.task_done()
class ThreadPool:
""" Pool of threads consuming tasks from a queue """
def __init__(self, num_threads):
self.tasks = Queue(num_threads)
for _ in range(num_threads):
Worker(self.tasks)
def add_task(self, func, *args, **kargs):
""" Add a task to the queue """
self.tasks.put((func, args, kargs))
def map(self, func, args_list):
""" Add a list of tasks to the queue """
for args in args_list:
self.add_task(func, args)
def wait_completion(self):
""" Wait for completion of all the tasks in the queue """
self.tasks.join()And the actual query code is fairly straightforward - just define a function that'll populate a global variable using some unique ID, and have it make the request off in its own thread.
urls = [f"https://jsonplaceholder.typicode.com/todos/{i}" for i in range(40)]
pool = ThreadPool(40)
r = requests.session()
def get(url):
resp = r.get(url)
results[i] = resp.json()
pool.map(get, urls)
pool.wait_completion()
Now we're getting somewhere - 40 requests in 365ms, or 9.125ms per request. The same 1000 requests that would've taken 1m10s earlier now finishes in a little over nine seconds, or just about a 7x speed up. Not bad for a pretty naive implementation of threading. Can we get it even faster, though?
Gen 3
A few years back I was introduced to the library aiohttp - which is Asynchronous HTTP Client/Server for asyncio and Python. This leverages the new (at the time) async capabilities of python and lose the actual overhead of Threads.
There is a bit of monkey patching I've had to do to make it work with all the various request types - specifically around its conformance to the cookie spec and to get it to work properly in jupyter notebook, where I like to play around with a lot of network requests.
Once we start looking at a pool of thousands of requests, we also want to be able to throttle ourselves - our laptops can only open so many TCP connections at once, and fire off so many bits in a given second. I defined a helper called gather_with_concurrency - it's a way of using asyncios gather with a semaphore, to limit the amount of tasks we work on in any given second.
This slows us down a bit due to the semaphore overhead, but if you're doing anything in the alphanumeric 4 digit space you're looking at 36^4, or 1.7m requests, which should probably be pooled and throttled a bit, and the overhead from the semaphore is worth it.
async def gather_with_concurrency(n, *tasks):
semaphore = asyncio.Semaphore(n)
async def sem_task(task):
async with semaphore:
return await task
return await asyncio.gather(*(sem_task(task) for task in tasks))Next we set up the connector and the custom session
conn = aiohttp.TCPConnector(limit=None, ttl_dns_cache=300)
session = aiohttp.ClientSession(connector=conn)Here we limit each host to none - it won't throttle itself internally, since we want to control that externally. We also bump up the dns cache TTL. For the purposes of this blog post this won't matter, but by default it's 10s, which saves us from the occasional DNS query.
Finally we define our actual async function, which should look pretty familiar if you're already used to requests. We also disable SSL verification for that slight speed boost as well.
async def get(url):
async with session.get(url, ssl=False) as response:
obj = await response.read()
all_offers[url] = obj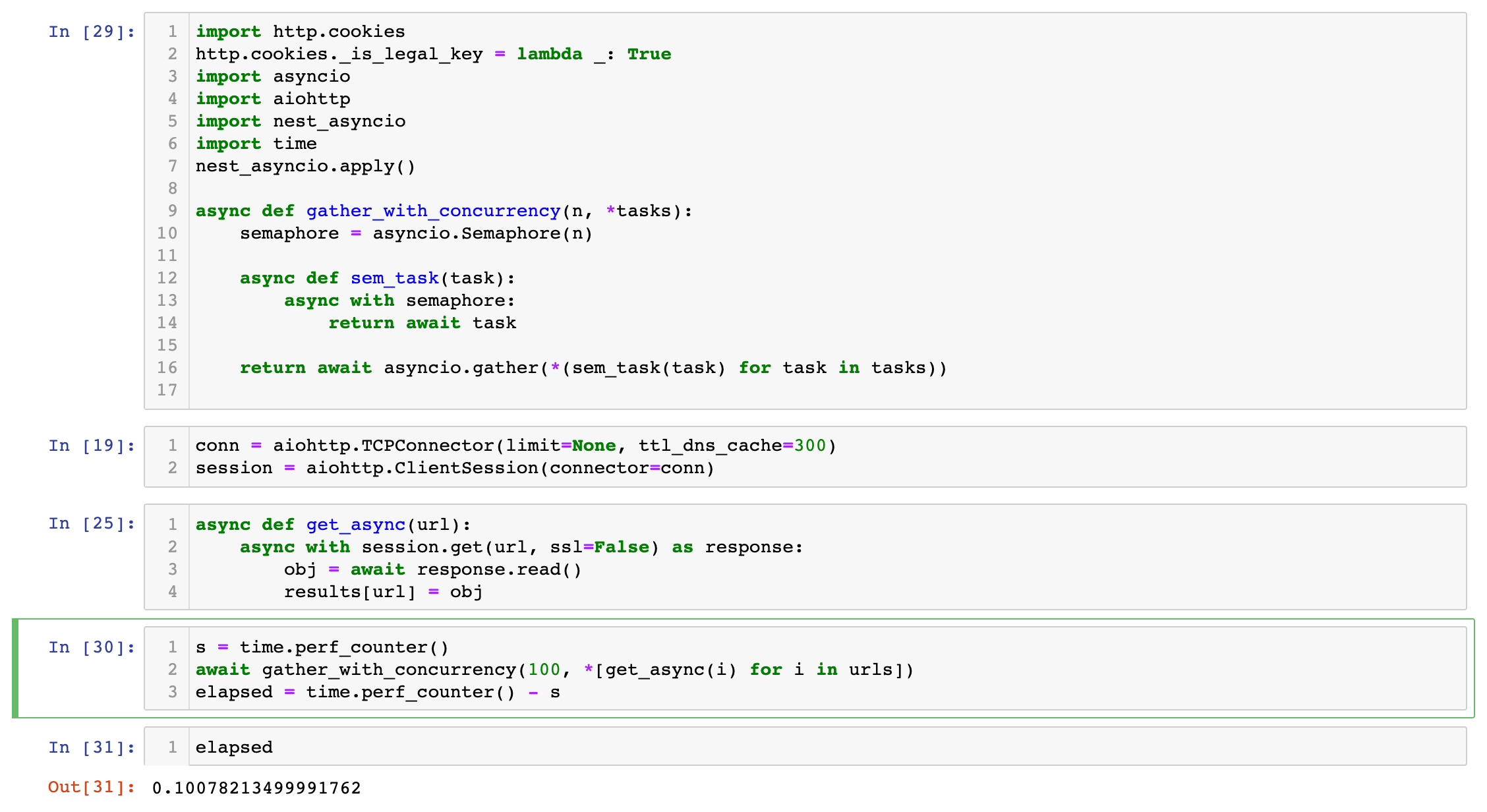
Now we're really going! 40 requests in 100ms, or 4ms per requests. We can do about 250 requests per second - however, at this speed, the overhead of the initial function set up and jupyter notebook is actually a significant portion of the overall cost.
If we bump it up to 4000 requests, we see that we actually get closer to a 1.574s execution time, or about 56% of the time it took us to make 10 requests iteratively.
We can make one request every 0.393ms, or 393 microseconds. We can blast through the entire alphanumeric space for a 4 character permutation in about 660 million microseconds, or 11 minutes, all from my MacBook pro.

Our Threading implementation also benefits from the increase in pool - giving it a 100 threads (the same as the semaphore in the asyncio version) gives us a time to completion of 8s for 4000 urls, or a little over 2ms per URL. Nowhere near our aiohttp implementation but not terrible either.

The same 36^4 requests using the ThreadPool would take 48 minutes, though.
We can clean up the code and optimize it slightly as well:
import sys
import os
import json
import asyncio
import aiohttp
# Initialize connection pool
conn = aiohttp.TCPConnector(limit_per_host=100, limit=0, ttl_dns_cache=300)
PARALLEL_REQUESTS = 100
results = []
urls = ['https://jsonplaceholder.typicode.com/todos/1' for i in range(4000)] #array of urls
async def gather_with_concurrency(n):
semaphore = asyncio.Semaphore(n)
session = aiohttp.ClientSession(connector=conn)
# heres the logic for the generator
async def get(url):
async with semaphore:
async with session.get(url, ssl=False) as response:
obj = json.loads(await response.read())
results.append(obj)
await asyncio.gather(*(get(url) for url in urls))
await session.close()
loop = asyncio.get_event_loop()
loop.run_until_complete(gather_with_concurrency(PARALLEL_REQUESTS))
conn.close()
print(f"Completed {len(urls)} requests with {len(results)} results")Optimal semaphore size?
If we bump our concurrent requests to 4k we see a drastic loss in performance.

This is nearly a 3x slow down due to resource contention issues locally.
The optimal number will depend on your host - beefier set ups will have higher concurrency limits, and if you're running this on a remote host on something like digital ocean you can crank this number up quite a bit.
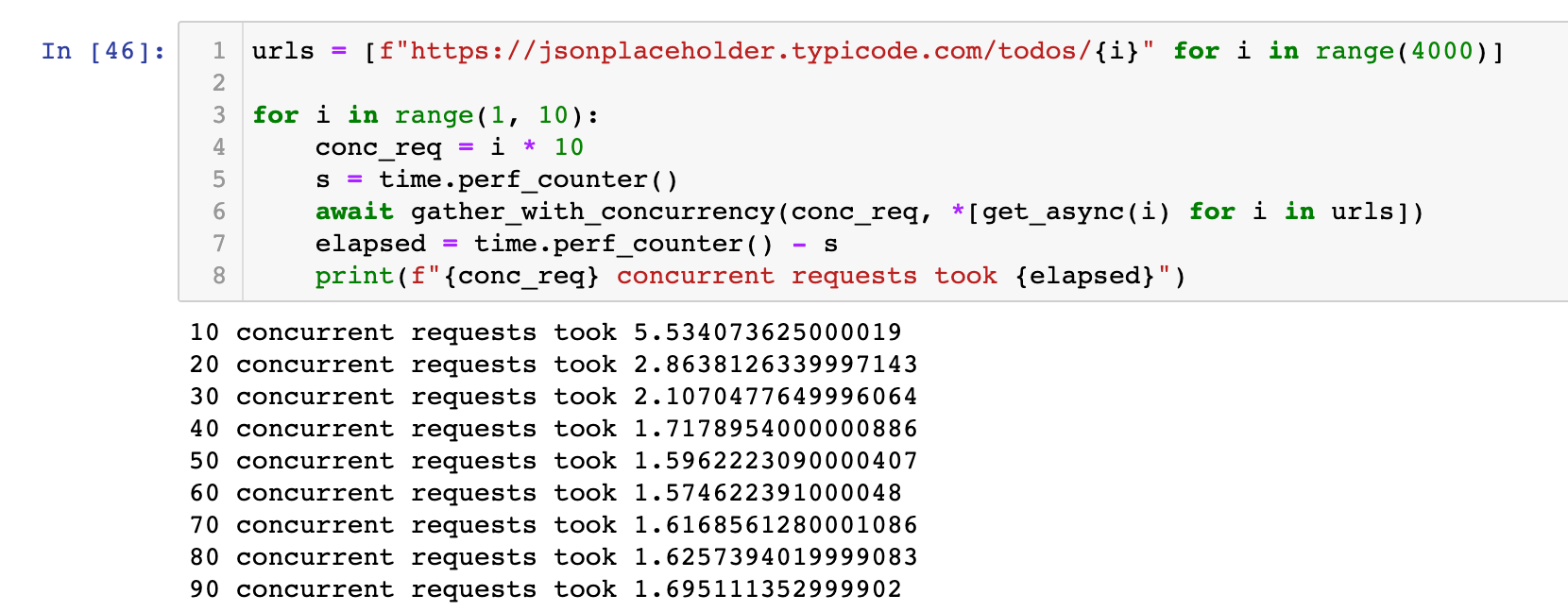
Interestingly enough the optimal semaphore value was right around 60.
I mostly do this locally at home, though, for my side projects - introducing parallelization and multiple hosts can get you numbers that are an order of magnituded better than this, but the purpose of this excercise is seeing what we can hit on a local machine with jupyter notebook.
Gen 4
Know of a faster implementation of an HTTP library that is stateful and works locally? Let me know!
HTTPX
Update - 6/17/21
A poster on lobste.rs said that I should try out httpx. HTTPX is a modern implementation of a python web client.
Unfortunately, in my testing, it was strictly slower than aiohttp. I used their async library with the same sempahore restricting the number of processes ran, but it was still slower.
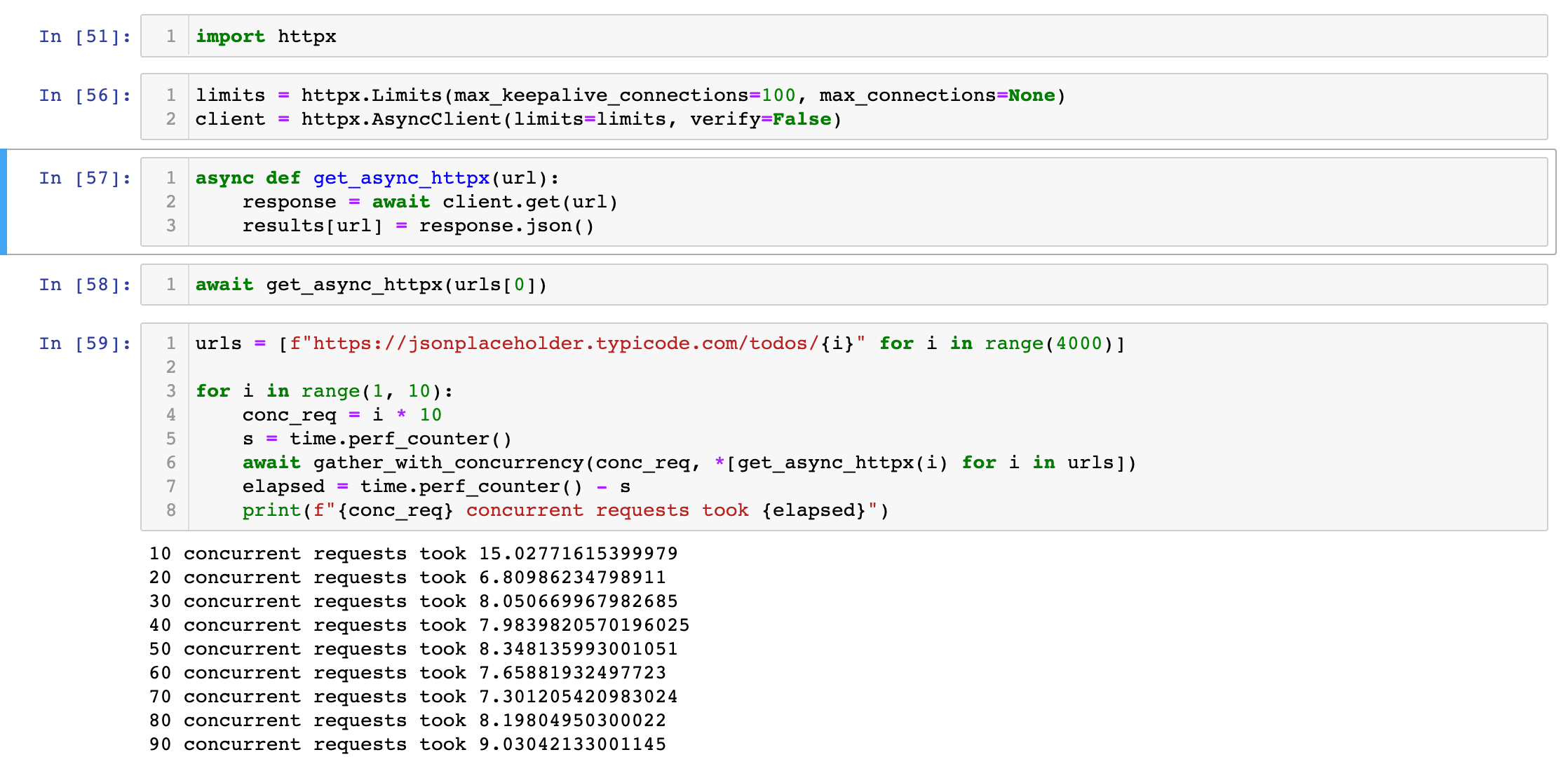
I also tried a native gather, with punting the concurrency down to the library - this did not help either.

PyCurl
Someone on that same lobste.er's thread suggested pycurl.
PyCurl is different in that it feels like a pretty raw wrapper to curl. Writing the code felt more like dispatching actions and opening sockets than dealing with a nice http library.
The results were impressive, but the aiohttp library was still faster. This was my first time writing a pycurl implementation, though, based on this template - introducing native threading might be able to speed it up, but I still haven't seen anything faster than the 393 microseconds approach.
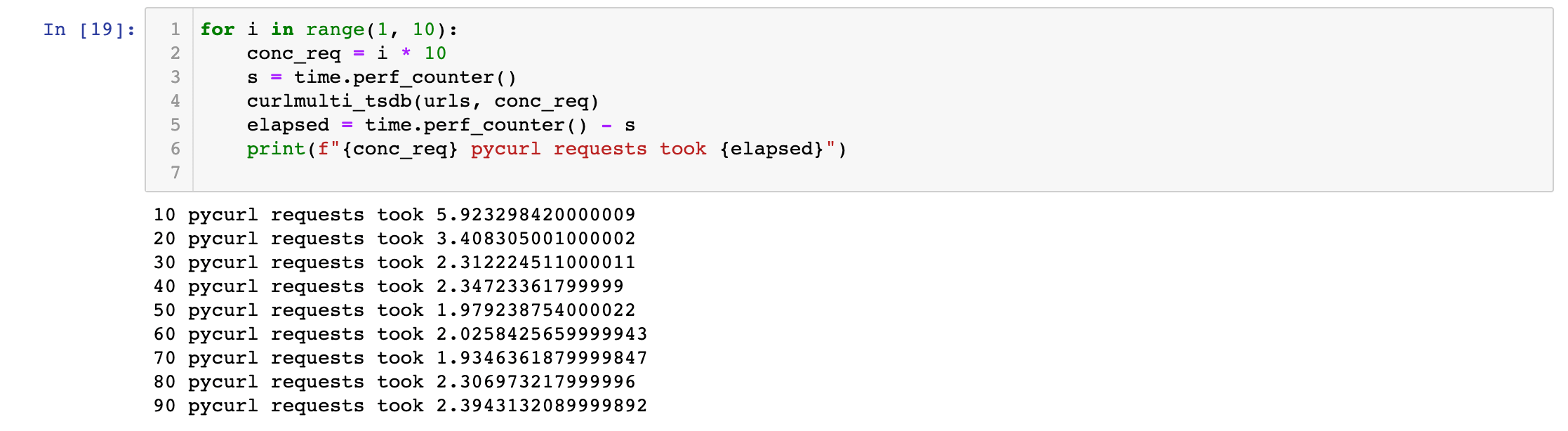
If you know how to set up HTTPX or PyCurl in a way that's faster let me know!
UVLoop
Addendum: 8/27/21 - I received an email from Steve telling me about uvloop, a faster, drop in replacement for asyncio's event loop.
It doesn't seem to have impacted the performance all that much - it did have lower variance, though. Across multiple runs of a regular asyncio event loop, I would get as high as 3s for the same 4000 requests; with uvloop, it never broke 2.1s.
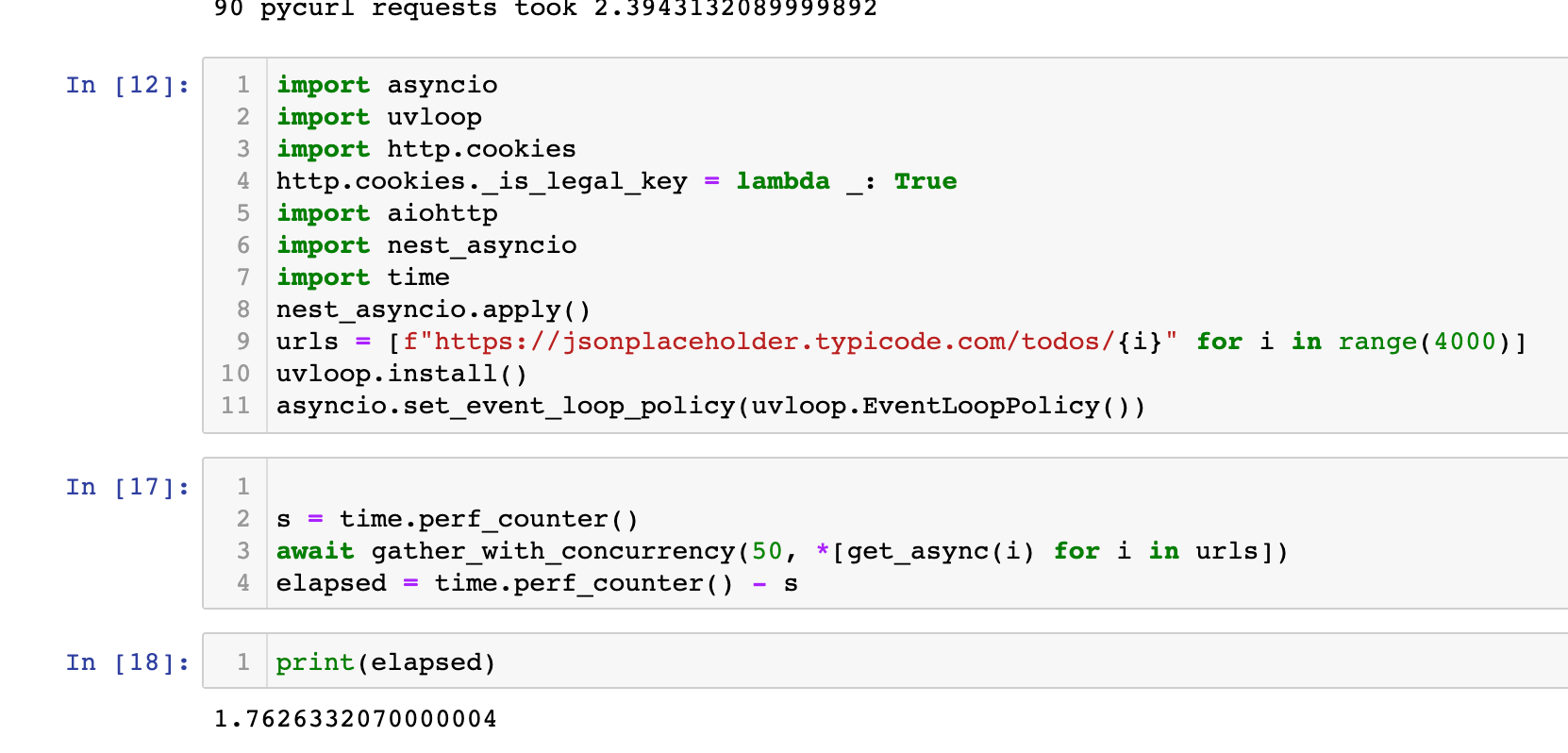
For a drop in replacement it seems pretty great - I don't think it'll help much at this stage, though, because most of the timing is due to the actual network call at this point. The threading and event loop implementation isn't adding that much overhead, I'm guessing.
